I started with toy models — modular addition, modular multiplication — using the commutator defect to look for what predicted grokking. The signal was real, but local. Scaling up to TinyStories pretraining, I found the backbone story: training trajectories concentrate along a single dominant direction. In GPT2-124M, the same structure appears with two dominant directions.
The natural question was the gap between the backbone and the rest — when does the dominant direction separate cleanly from the bulk? Going back to the toy models with that question, σ2/σ3 on the rolling parameter-update Gram fell out as the right object.
From there, two further applications: the σ2/σ3 eigengap as a Stage III lock-in detector in Tian’s Li2 framework, and per-task gradient SVD revealing 100–330× Linear-Centroid coupling. Others are in progress.
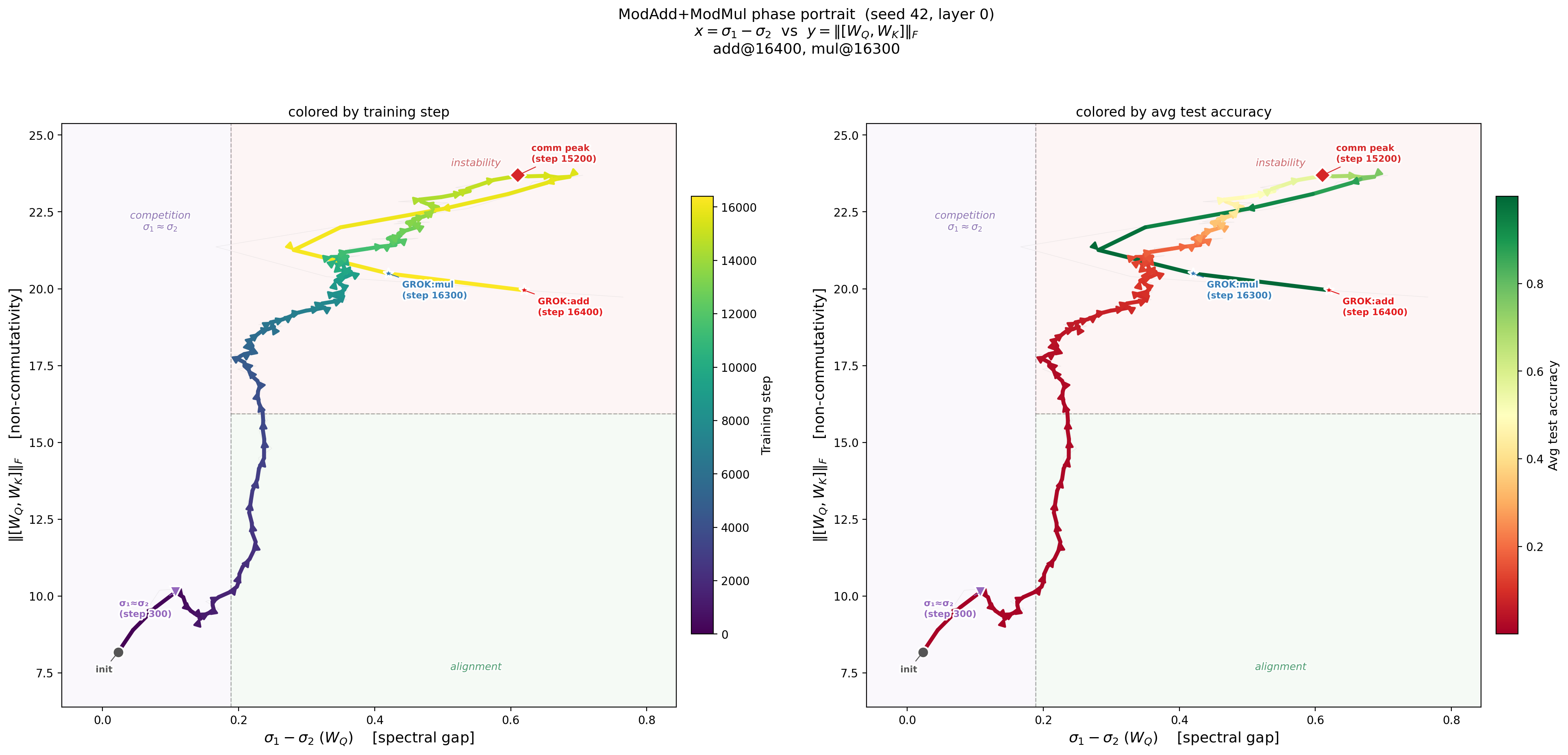
Phase Portrait of Grokking
Left: Training trajectory in the (spectral gap, non-commutativity) plane, colored by training step. The system wanders in the competition zone (σ₁ ≈ σ₂) with near-zero accuracy, then the gap opens, non-commutativity peaks at step 15200, and the trajectory crosses into the alignment quadrant — at which point both grokking events occur (ModMul at step 16300, ModAdd at step 16400). Right: The same trajectory colored by test accuracy. Accuracy is essentially zero until the phase portrait dictates otherwise.
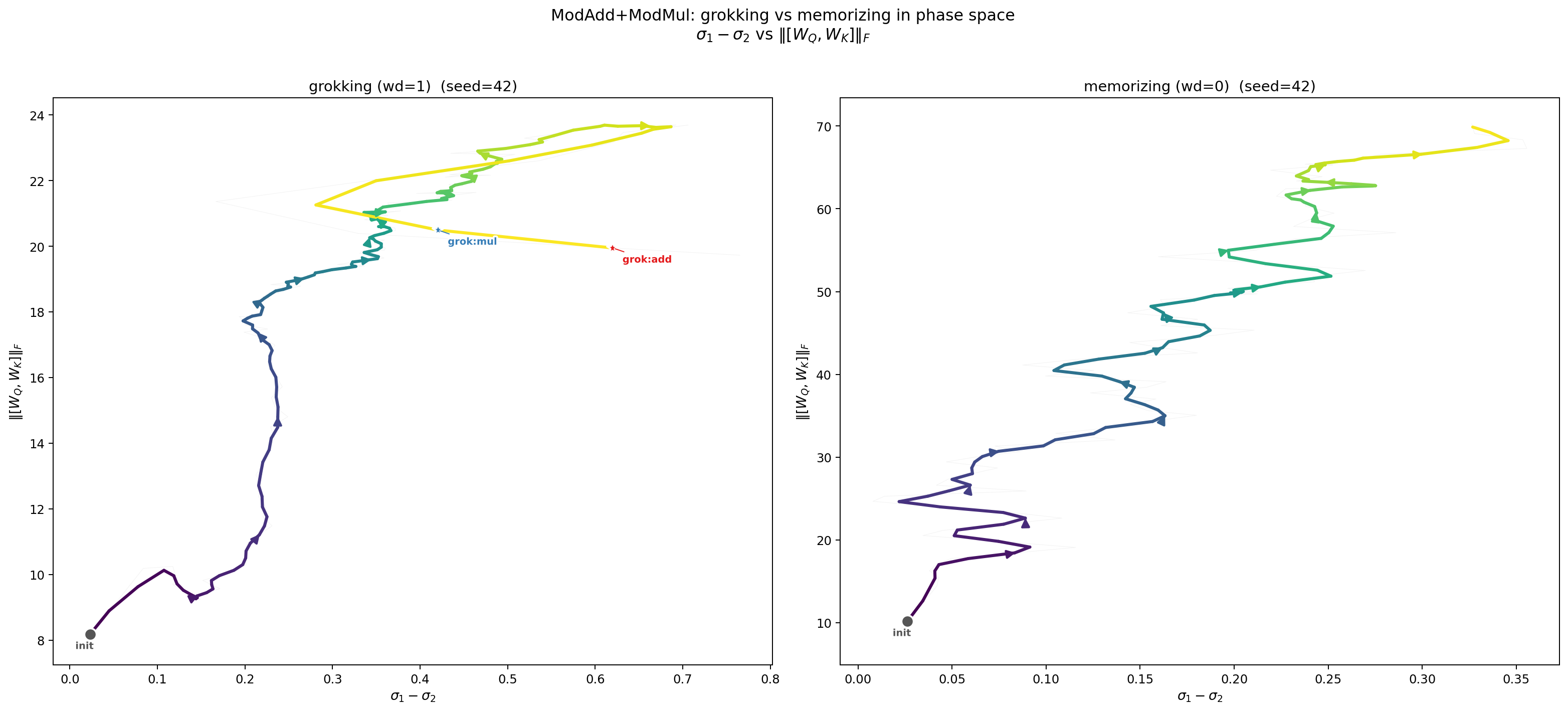
Grokking vs. Memorizing in Phase Space
Two runs, same architecture, same seed. With weight decay (left), the spectral gap opens and the system generalizes. Without weight decay (right), the gap never opens — the trajectory expands in the vertical direction but stays compressed along the spectral axis. The distinction between generalization and memorization is visible in the geometry of the training trajectory.
Notes & writeups
An unsupervised spectral signal pre-identifies causally-relevant attention heads across an ~20× parameter scale range (51M synthetic to OLMoE 1B-7B), two architectures (dense + 64-expert MoE), and three pretraining datasets (Pile, FineWeb, DCLM). Universal cross-architecture finding: L0/L1 have zero BOS-classified heads in every model tested; a 3–4 head induction circuit is identified in every 1B-class model via a capability-specific screen at selectivity ≥ 50×.
Research Overview
My research applies geometric and dynamical-systems methods — geometric flows, Morse theory, critical-point theory, variational methods — to questions about training dynamics, capability emergence, and representation structure.
Develops the analytical machinery for the spectral edge phenomena observed across earlier work: gap dynamics equations, a spectral loss decomposition, and an adiabatic parameter for training stability. Verified across modular arithmetic, Dyck-1, SCAN, and GPT2-class transformer training.
Note on the scope. The empirical predictions — phase transition timing, grokking onset — are robust across architectures and scales. The theoretical definition of the privileged subspace boundary k* remains an open problem. For simple datasets the definition is operationally clean; for complex datasets like natural language, the edge may be a more diffuse object without a single privileged direction. This is the next theoretical question the framework raises, not a limitation of the empirical results.
Spectral-Edge Notes & Papers
Per-task gradient SVD bridges Linear-Centroid features and spectral-edge optimizer dynamics with 100–330× coupling — 1–2 orders of magnitude stronger than the AdamW-update SVD used in prior work.
Bridges to Yuandong Tian’s Li2 grokking framework (arXiv:2509.21519): the σ2/σ3 eigengap on the rolling parameter-update Gram pinpoints Tian’s Stage III lock-in (fires at epoch 174 ± 1 in 15/15 grok seeds, 0/15 controls), with Theorem 6 sign-match saturating at the same epoch — mechanistic verification of when feature repulsion becomes dominant.
At grokking, the spectral edge transitions from a gradient-driven functional axis to a weight-decay compression axis — flat under perturbation yet >4000× more ablation-critical than random directions.
Each spectral-edge direction induces a structured function over the input domain — a single Fourier mode for modular addition, a discrete-log mode for multiplication, a multi-mode family for subtraction — invisible to standard interpretability tools.
Empirical Evidence
Scales spectral-edge analysis to GPT2-class transformer training (51M–124M parameters): the coherent/noise boundary follows a universal three-phase evolution and effective signal rank scales with task complexity.
Transformer trajectories under AdamW concentrate along a “backbone” direction capturing 60–80% of displacement from initialization; the effect vanishes under SGD, identifying the structure as optimizer-induced rather than gradient-induced.
Multi-task modular-arithmetic trajectories live in a 2–6 dimensional global subspace while individual weights remain full-rank: learned algorithms are globally low-rank in learning directions but locally full-rank in parameter space.
Weight decay drives a phase diagram of multi-task grokking dynamics — staggered task ordering, universal trajectory integrability, holographic incompressibility, and transverse fragility — consistent with compression onto a superposition subspace.
Training evolves within a single dominant component (68–83% variance) while orthogonal curvature spikes ahead of grokking with a power-law lead time; causal intervention confirms motion along the subspace is necessary for generalization.
The commutator defect rises before grokking on SCAN and Dyck-1, accelerates grokking by 32–50% when amplified, and prevents it when suppressed — a causally implicated, architecture-agnostic early-warning signal.
Transformer training on modular arithmetic collapses onto 3–4 dimensional execution manifolds, with most parameters absorbing optimization interference while computation occurs in a dramatically reduced subspace.
Collaboration
I’m interested in how neural networks learn, and how they could learn better. I want the work to be useful. Everything I do comes out of that.
Collaborations are welcome — theoretical or empirical, on current questions or new ones. Visiting positions, joint research projects, or other engagements with researchers in mechanistic interpretability, alignment, or large-scale training all welcome.
I received my Ph.D. in Mathematics from Rutgers University, where I worked with Abbas Bahri in nonlinear PDE and contact geometry. I was subsequently a Courant Instructor at the Courant Institute of Mathematical Sciences (NYU) and a member of the Institute for Advanced Study. I later served as a Distinguished Research Fellow and Associate Professor at Shanghai Jiao Tong University.
Outside of work, I have been practicing meditation in the Nyingma tradition since sixteen. I enjoy hiking and cooking. I am a vegetarian.